Automatically Evaluating AI Coding Assistants with Each Git Commit
AI coding assistants are performing an ever-increasing share of software engineering work. Generic LLM coding benchmarks fail to capture the effectiveness of a coding assistant for specific use cases and workflows.
How can you measure what works (and doesn’t work) for you specifically?
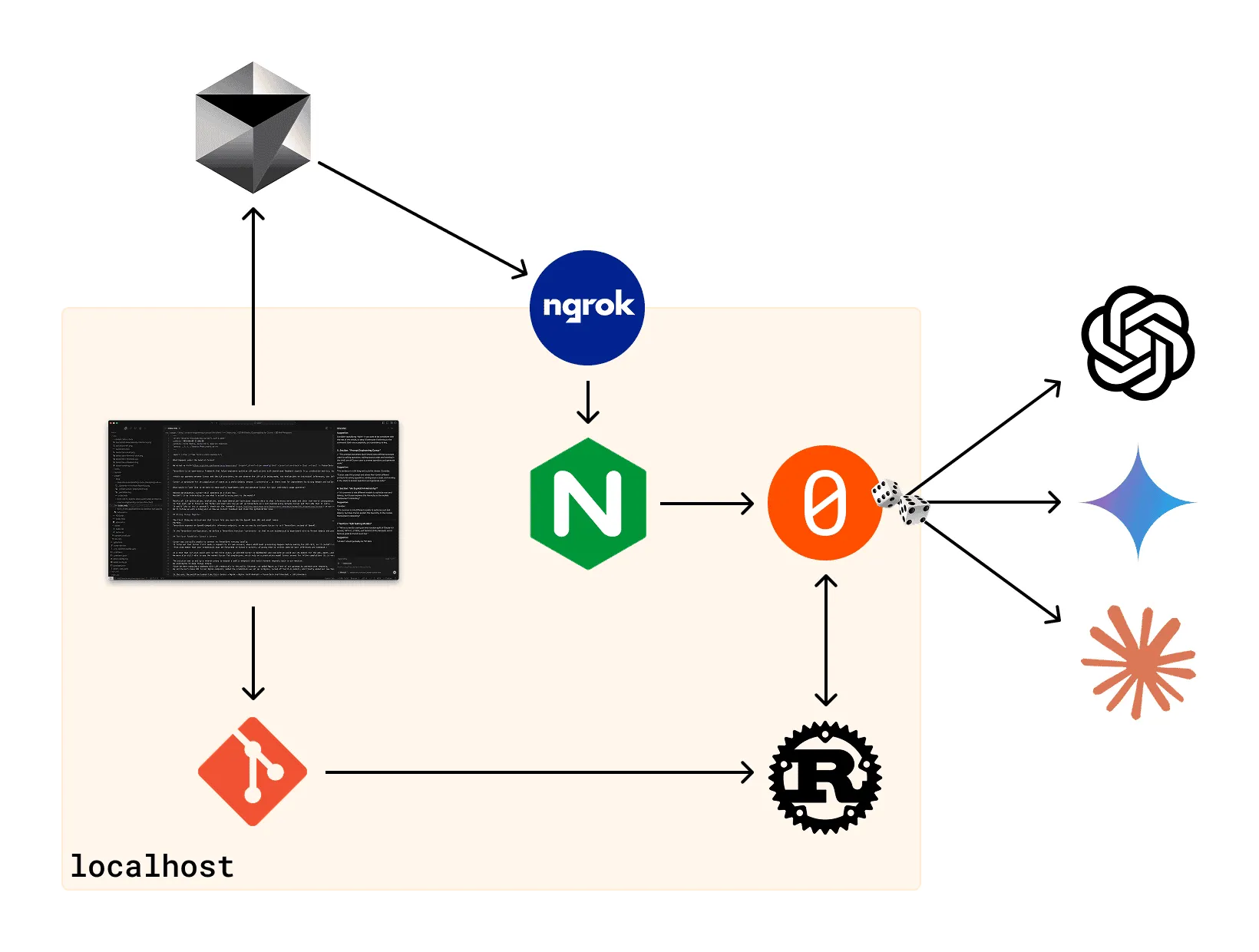
In Reverse Engineering Cursor’s LLM Client, we used 11.5KTensorZero (open-source LLM gateway, observability, optimizations, evaluations, experimentation) to store data on each inference Cursor made in our own database and even configure A/B tests over LLMs and additional prompts for these inferences. Naturally, we wanted to know which prompts and models were performing better.
This post describes our methodology for automatically evaluating the tangible impact of coding agents in our day-to-day software engineering process.
Our work does not claim that a particular model is superior to another in a general way. We believe that this is the obvious role for benchmarking. Instead, we focus on local evaluation for individual engineering use cases and workflows.
TensorZero was designed from the ground up to collect feedback (e.g. metrics, human edits) about LLM inferences. We simply needed to figure out a way to measure how helpful particular Cursor inferences are. This feedback loop can guide experimentation and eventually optimization workflows in TensorZero — tailored to the usage of an individual engineer.
Every programmer maintains a structured record of the code that they think is worth keeping: the commit log in their version control system. Could we use our Git commits to derive feedback for the inferences we are collecting from Cursor?
We identified many challenges from the start:
- We’d need to link git commits to the set of inferences that might have contributed to it.
- Each commit might contain a mix of code written by a human, code generated across many inferences, etc.
- Some changes to the code are semantically meaningful while others are very much not. This depends greatly on the programming language being used.
- To avoid disrupting our engineering workflow, feedback must be collected automatically (and quickly!) with each commit.
- We need to distinguish between inferences that directly generate code and those that contribute indirectly (e.g. planning, shell commands). For agentic systems like Claude Code, understanding the relationship between those inferences is particularly useful.
Though we don’t solve all these challenges in this post, we came to an extensible, performant, and open-source solution that we believe addresses many of these concerns. You should be able to run it on your own machine with a handful of commands if you’ve already deployed the Cursor integration presented in our previous post.
Calculating a robust reward for coding agents
We started by considering the simplest setting: one inference and one commit. Our goal was to measure the difference between the generated code and the committed code.
The naive approach was to use Levenshtein distance, a metric that calculates the smallest number of character changes (insertions, deletions, or substitutions) needed to transform a string into another. However, we immediately realized that there would be many inconsequential edits picked up by this metric.
For example, in Python, the following change has a tiny Levenshtein distance (2 character additions) but materially affects the behavior of the code by changing operator precedence:
result = a + b * cresult = (a + b) * cMeanwhile, in Rust, the following change, with much higher Levenshtein distance, is semantically identical.
fn f(x: &str) { println!(x); }fn log_critical_error_message(critical_error_message: &str) {
println!(critical_error_message);
}The ideal metric should consider the programming language being used and the actual behavior of the code when executed.
Luckily, from our experience futzing about with neovim configs, we knew exactly what to reach for here.
tree-sitter is an excellent library used for incremental parsing of source code into a concrete syntax tree for highlighting, linting, and many other features of code editors.
Using tree-sitter, we were able to convert a code snippet into an in-memory tree structure, where each node represents a language-specific element (e.g. functions, variables, operations) parsed from the code.
Visualization: tree-sitter
This meant we could reason about code parsed as semantically meaningful objects rather than raw text.
Edit distances on trees
Next, we needed to figure out how to compare the similarity between two such syntax trees.
We reached for a generalization of Levenshtein distance known as tree edit distance (TED). The TED between a pair of trees is defined to be the minimum number of operations to transform one into another by inserting, deleting, and relabeling nodes. The standard technique for computing tree edit distance is the Zhang-Shasha algorithm, which uses dynamic programming to calculate the tree edit distance in time where is the tree size.

The tree edit distance between these two trees is 3. This means it takes three operations (insertions, relabelings, or deletions) to transform the tree on the left into the tree on the right.
With this combination of tree-sitter and TED, we were able to calculate a distance metric between a pair of code snippets that is language-aware and semantically meaningful.
If a diff falls in a forest…
But inferences and commits are really forests, not trees.
LLM outputs frequently include several discrete code snippets rather than a single block. Likewise, a commit can introduce multiple, separate chunks of code. Our real task is to align each snippet generated by the LLM with the corresponding chunk in the commit.
To tackle it, we first parse every snippet into a tree.
For each LLM snippet, we search the commit for the subtree with the smallest tree-edit distance (TED).
The algorithm exhaustively evaluates every candidate subtree to guarantee the closest match.
Each distance is normalized by the size of the LLM snippet, yielding a ratio in [0, 1].
We then average these ratios across all snippets in the inference, and compute the reward is then computed as 1 - average_ratio.
A perfect match receives a score of 1, while lower scores indicate poorer performance.
A bit more formally…
Formally, say that an LLM inference outputs code snippets with corresponding concrete syntax trees ; this is a set of trees (or, a forest). Similarly, a commit has an associated forest where each is parsed from a contiguous segment of added code from the commit.
Each inference tree from the set can potentially match any rooted subtree within the commit forest , denoted as . To determine the best match, we calculate a distance for each inference tree. This distance is defined as the minimum tree edit distance (TED) between an and any subtree .
The Zhang-Shasha algorithm requires trees to be traversed in post-order, so we first compute the post-order traversal of each tree (later, this also helps us iterate over all rooted subtrees). Then, for each subtree , we calculate the tree edit distance and find the minimum. This process is repeated for each code snippet in the inference to determine the distance .
We keep track of the subtree that has the smallest distance, along with the distance value itself. An important point to note is that , i.e. the TED between two trees, and , is always less than the maximum of their sizes, . This allows us to normalize the distance by dividing it by the size of the generated code snippet’s tree.
To summarize the results, we calculate a global ratio . This global ratio represents the average TED normalized by . Since this ratio is between 0 and 1, and we aim to maximize rewards, we define the overall reward for an inference as .
The visualization below shows how inference trees are matched against all possible subtrees in a commit forest using Tree Edit Distance (TED).
Visualization: Subtree Search in Forest TED Matching
- Current Comparison: -
- TED(t1, current_subtree): -
- Current Ratio: -
- Current Reward: -
- Best Distance Found: ∞
- Best Normalized Ratio r1: -
- Best Reward (1 - r1): -
Automatically collecting feedback using TED
We implemented a small binary in Rust that can be run as a post-commit git hook to automatically collect feedback on the Cursor inferences used to generate the commit.
After each commit, the binary runs the following process:
- Extract the committed changes and break them down into sections of consecutive added lines (known as hunks in
gitterminology). - Retrieve all relevant inferences from ClickHouse that were made between the last commit and the current one. Ensure these inferences have no feedback yet and were made by the same user, if a user is specified.
- Utilize the
tree-sitterRust crate to analyze the syntax of each hunk and each inference. - Calculate the reward value for each inference as explained above and submit as feedback to TensorZero for each inference.
- Additionally, substitute the generated code block with the code that minimizes the tree edit distance (TED) from the set of possible subtrees in the commit, and send this revised code as demonstrations to TensorZero.
Since the heavy computations of computing edit distances are compute-bound and embarassingly parallel, we use the excellent rayon crate to parallelize this workflow across CPUs.
We haven’t observed these computations to be a performance bottleneck with this implementation, even on large commits with dozens of inferences.
Over time, this results in a rich dataset of inferences with quantitative and qualitative feedback that can be used to understand the performance of different prompts and models that we configured.
Some early results and observations
Coding is noisy! We ask our coding agents for a lot of different information and only some of it ends up as commited code.
That being said, Viraj (TensorZero’s CTO) saw that GPT-4.1 was less effective than Claude 3.7 Sonnet, Gemini 2.5 Pro, and o4-mini — for his individual coding patterns. Below are some preliminary results.
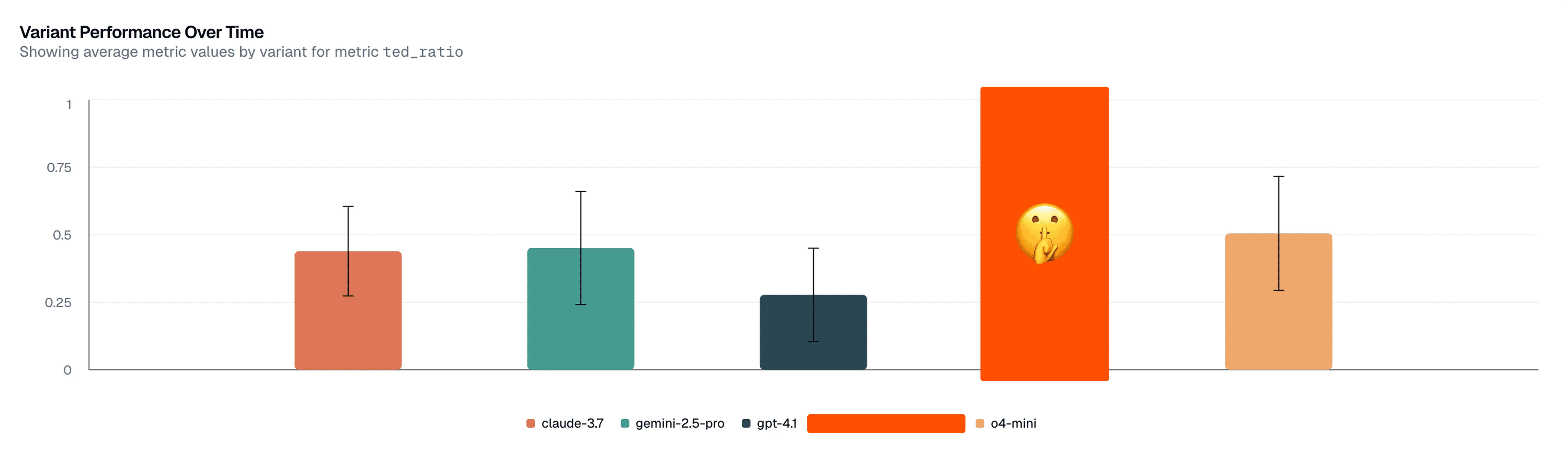
Given a noisy environment where we’d like to infer the causal relationship between a choice of LLM (and prompt, hyperparameters, etc.) and coding performance, the only good technique is to randomize your trial. TensorZero supports this kind of experimentation out of the box, and as we collect more data, we may find out more about our team’s use patterns and which models perform best.
Future work
We are currently using this workflow in production to see how each engineer on our team uses AI tooling and identify patterns in their aggregate usage.
Admittedly, this post surfaces more questions than answers. Here are some questions we are investigating using this methodology for future posts:
- Does the performance of popular models vary by programming language or by engineer?
- Do slower, more expensive models deliver significantly better results on real-world, human-assisted workflows?
- How do models from Chinese labs stack up against those from American labs?
- How do recent text-diffusion models (e.g. Gemini Diffusion, Mercury Coder) compare with traditional autoregressive models?
- How does our reward metric correlate with the size of the input context, generated output, and commit? What about different programming languages?
- How do hyperparameters like thinking effort and temperature affect these workflows?
As we collect more data over time, we may arrive at a point where it is feasible to use it to directly optimize the prompts and models used by our team. It remains an open question whether it would make sense to fine-tune or reinforce a model on this data or to use lighter-weight techniques like dynamic in-context learning.
We’re also planning to expand TensorZero’s experimentation functionality with built-in multi-armed bandit algorithms. This feature will allow us to intelligently redirect traffic to the most effective variants based on the feedback we receive.
We also see related workflows in the software development lifecycle that could benefit from the same feedback stream as this project. See our case study Automating Code Changelogs at a Large Bank with LLMs for prior work on a production-grade automated feedback loop for such a task.
More broadly, 11.5KTensorZero is an open-source stack for industrial-grade LLM applications. It unifies an LLM gateway, observability, optimization, evaluation, and experimentation. You can get started in minutes, adopt incrementally, extend with other tools, and scale to the most complex deployments and billions of inferences. Over time, TensorZero enables a data and learning flywheel for optimizing LLM applications — a feedback loop that turns metrics and human feedback into smarter, faster, and cheaper models.
What is the best AI coding assistant for you? We will continue studying this question over the coming weeks and months. Stay tuned by subscribing below.