Reverse Engineering Cursor's LLM Client
What happens under the hood at Cursor?
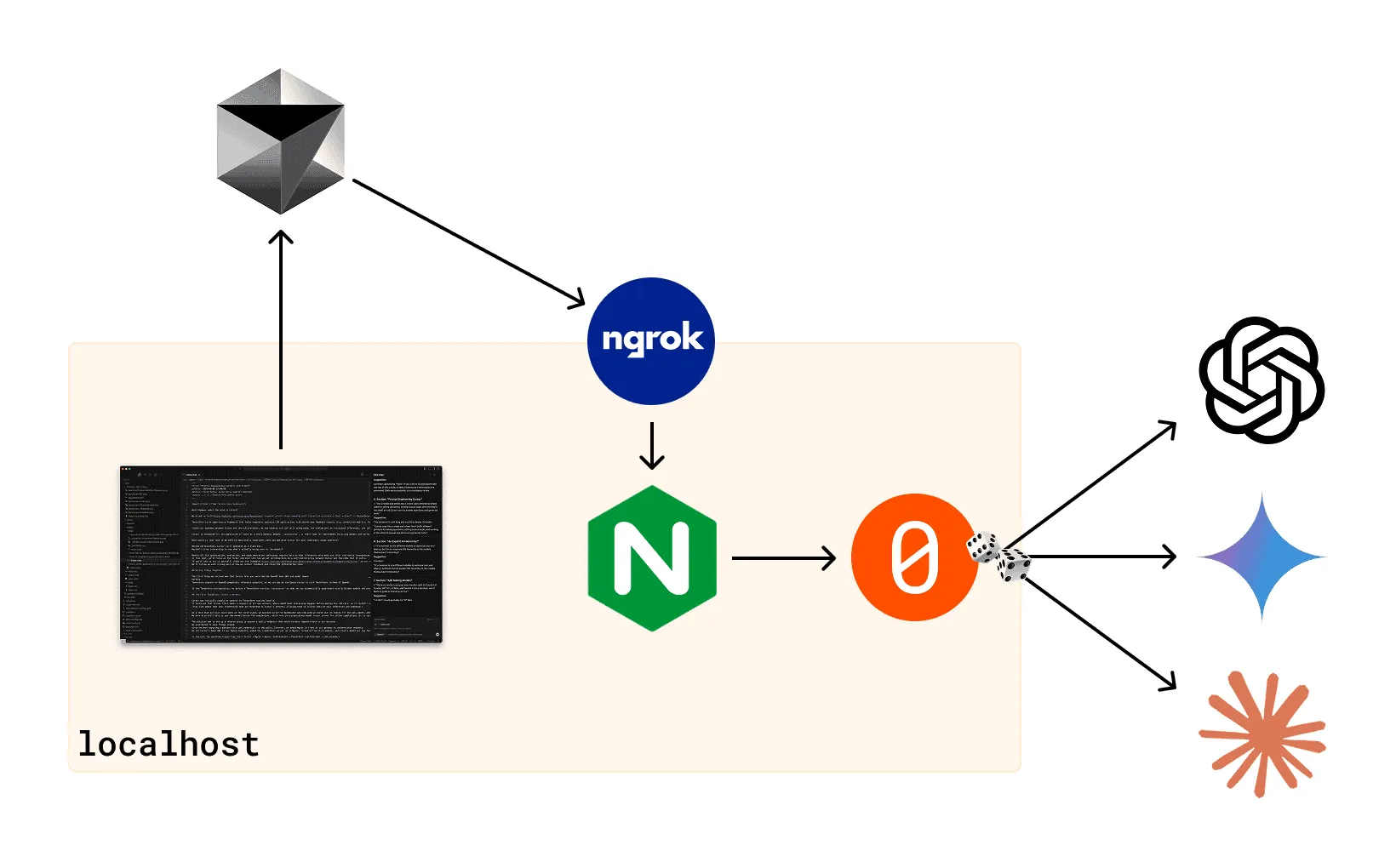
We wired 11.0KTensorZero between Cursor and the LLMs to see every token fly by… and bend those API calls to our own will.
TensorZero is an open-source framework that helps engineers optimize LLM applications with downstream feedback signals (e.g. production metrics, human feedback, user behavior), and we figured it would be interesting to see whether we could use TensorZero on the LLM application we use most heavily ourselves: Cursor.
With our gateway between Cursor and the LLM providers, we can observe the LLM calls being made, run evaluations on individual inferences, use inference-time optimizations, and even experiment with and optimize the prompts and models that Cursor uses.
Cursor is optimized for its population of users as a whole — beyond .cursorrules, is there room for improvement by diving deeper and tailoring it to individual users?
What would it look like to be able to empirically experiment with and optimize Cursor for your individual usage patterns?
Beyond optimization, Cursor still operates as a black box. Wouldn’t it be interesting to see what’s actually being sent to the models?
Nearly all LLM optimization, evaluation, and experimentation techniques require data on what inferences were made and their real-world consequences. In this post, we’ll focus on the former and dive into how we set up TensorZero as a self-hosted proxy between Cursor and the LLMs that it calls. If you’d like to try it yourself, check out the example in our repository. We’ll follow up with a blog post on how we collect feedback and close the optimization loop.
Wiring Things Together
The first thing we noticed was that Cursor lets you override the OpenAI base URL and model names. Perfect. TensorZero exposes an OpenAI-compatible inference endpoint, so we can easily configure Cursor to call TensorZero instead of OpenAI.
In the TensorZero configuration, we define a TensorZero function cursorzero so that we can automatically experiment with different models and prompts while storing provider-agnostic inference and feedback data in our database for observability and optimization.
The First Roadblock: Cursor’s Servers
Cursor was initially unable to connect to TensorZero running locally.
It turns out that Cursor first sends a request to its own servers, where additional processing happens before making the LLM call, so it couldn’t connect to our gateway on localhost.
(This also means that your credentials must be forwarded to Cursor’s servers, allowing them to collect data on your inferences and codebase.)
As a test that our plan could work in the first place, we pointed Cursor to OpenRouter and realized we could use its models for the Ask, Agent, and Cmd+K interactions in Cursor. We were also still able to use the normal Cursor Tab completions, which rely on a proprietary model Cursor serves for inline completions (it is very good, so we’re glad to be able to keep it).
The solution was to set up a reverse proxy to expose a public endpoint that would forward requests back to our machine.
We used Ngrok to keep things simple.
Since we were exposing a gateway with LLM credentials to the public Internet, we added Nginx in front of our gateway to authenticate requests.
We set Cursor’s base URL to our Ngrok endpoint, added the credentials we set up in Nginx, turned off built-in models, and finally added our new TensorZero function under the model name tensorzero::function_name::cursorzero.
In the end, the workflow looked like this: Cursor → Ngrok → Nginx (self-hosted) → TensorZero (self-hosted) → LLM providers
But it didn’t work.
The Second Roadblock: CORS
The authentication process had failed.
Nginx logs showed that there was an OPTIONS request hitting our endpoint, so we configured Nginx to return headers on OPTIONS requests and incrementally added headers we saw in responses from the OpenAI API.
This is the initial verification request that comes from the local Cursor IDE.
The CORS requirement likely comes from Electron.
After the initial verification, all requests come from Cursor’s servers.
Our Nginx Configuration to handle CORS headers
# --- CORS helper macro ---
set $CORS_ALLOW_ORIGIN $http_origin; # reflect the caller's origin
set $CORS_ALLOW_HEADERS "Authorization,Content-Type";
location / {
# --- pre-flight ---
if ($request_method = OPTIONS) {
add_header Access-Control-Allow-Origin $CORS_ALLOW_ORIGIN always;
add_header Access-Control-Allow-Credentials "true" always;
add_header Access-Control-Allow-Methods "GET,POST,OPTIONS" always;
add_header Access-Control-Allow-Headers $CORS_ALLOW_HEADERS always;
add_header Access-Control-Max-Age 86400 always;
return 204; # 204 (No Content) is conventional for pre-flight
}
}You can find the entire codebase for “CursorZero” on GitHub.
It finally worked!
Finally: Observability for Cursor
We could finally see everything coming in and out of Cursor — including its prompts.
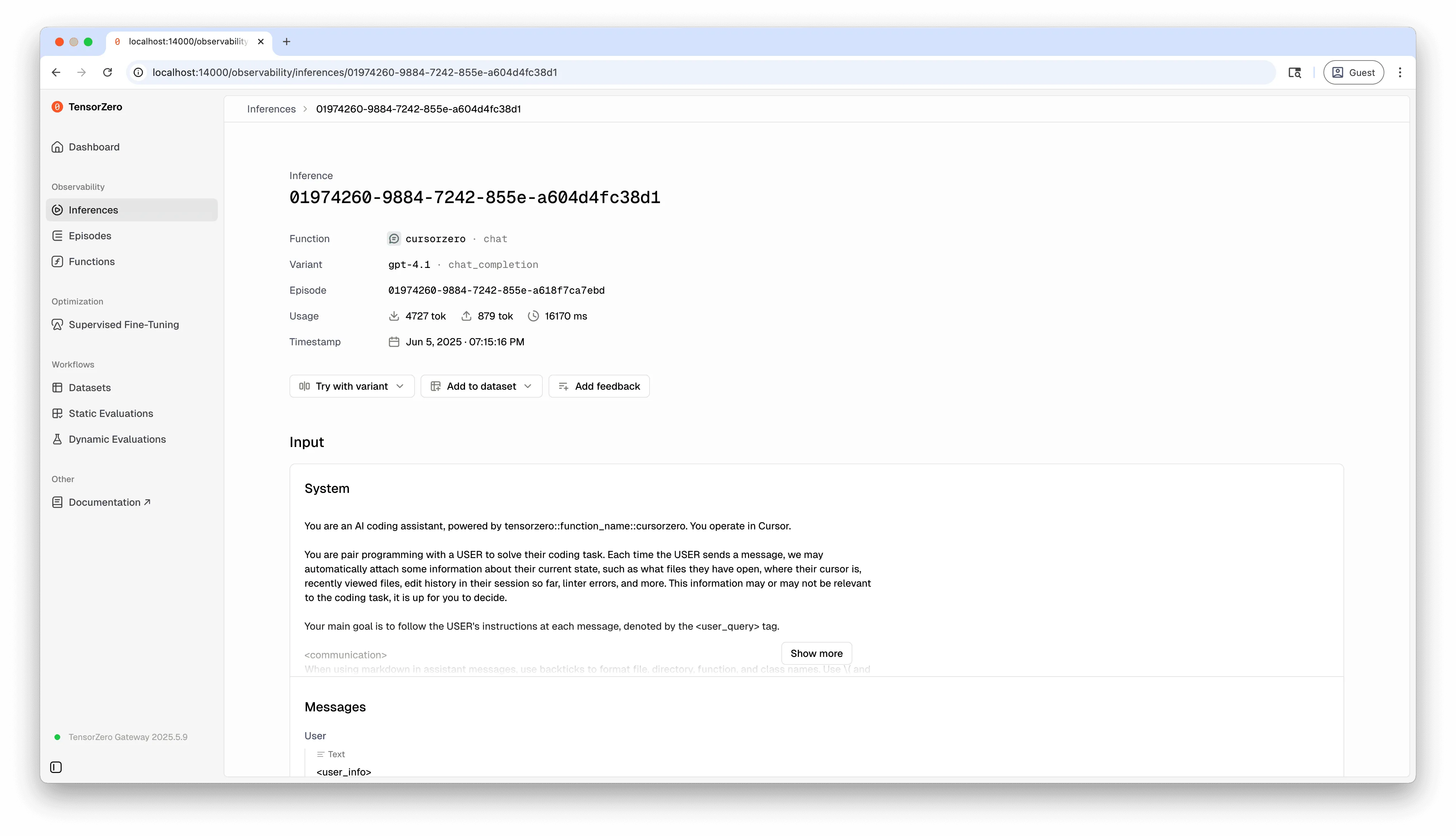
For example, here’s what we saw after asking Cursor “how do I get nginx to get the key from an environment variable in my .env?”
System Prompt
You are a an AI coding assistant, powered by tensorzero::function_name::cursorzero. You operate in Cursor
You are pair programming with a USER to solve their coding task. Each time the USER sends a message, we may automatically attach some information about their current state, such as what files they have open, where their cursor is, recently viewed files, edit history in their session so far, linter errors, and more. This information may or may not be relevant to the coding task, it is up for you to decide.
Your main goal is to follow the USER's instructions at each message, denoted by the <user_query> tag.
<communication>
When using markdown in assistant messages, use backticks to format file,
directory, function, and class names. Use ( and ) for inline math, [ and ]
for block math.
</communication>
<search_and_reading>
If you are unsure about the answer to the USER's request or how to satiate their request, you should gather more information. This can be done by asking the USER for more information.
Bias towards not asking the user for help if you can find the answer yourself.
</search_and_reading>
<making_code_changes>
The user is likely just asking questions and not looking for edits. Only suggest edits if you are certain that the user is looking for edits.
When the user is asking for edits to their code, please output a simplified version of the code block that highlights the changes necessary and adds comments to indicate where unchanged code has been skipped. For example:
```language:path/to/file
// ... existing code ...
{{ edit_1 }}
// ... existing code ...
{{ edit_2 }}
// ... existing code ...
```
The user can see the entire file, so they prefer to only read the updates to the code. Often this will mean that the start/end of the file will be skipped, but that's okay! Rewrite the entire file only if specifically requested. Always provide a brief explanation of the updates, unless the user specifically requests only the code.
These edit codeblocks are also read by a less intelligent language model, colloquially called the apply model, to update the file. To help specify the edit to the apply model, you will be very careful when generating the codeblock to not introduce ambiguity. You will specify all unchanged regions (code and comments) of the file with "// ... existing code ..." comment markers. This will ensure the apply model will not delete existing unchanged code or comments when editing the file. You will not mention the apply model.
</making_code_changes>
<user_info>
The user's OS version is darwin 24.3.0. The absolute path of the user's workspace is /Users/viraj/tensorzero/tensorzero/examples/cursorzero. The user's shell is /bin/zsh.
</user_info>
You MUST use the following format when citing code regions or blocks:
```12:15:app/components/Todo.tsx
// ... existing code ...
```
This is the ONLY acceptable format for code citations. The format is ```startLine:endLine:filepath``` where startLine and endLine are line numbers.User Prompt
<additional_data>
Below are some potentially helpful/relevant pieces of information for figuring out to respond
<current_file>
Path: nginx/nginx.conf
Line: 1
Line Content: `events {}`
</current_file>
<attached_files>
<file_contents>
```path=nginx/nginx.conf, lines=1-46
events {}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent"';
access_log /var/log/nginx/access.log main;
map $http_authorization $is_authorized {
default 0;
"~*^Bearer your-token-here$" 1;
}
server {
listen 80;
# --- CORS helper macro ---
set $CORS_ALLOW_ORIGIN "$http_origin"; # reflect the caller's origin
set $CORS_ALLOW_HEADERS "Authorization,Content-Type";
location / {
# --- pre-flight ---
if ($request_method = OPTIONS) {
add_header Access-Control-Allow-Origin "$CORS_ALLOW_ORIGIN" always;
add_header Access-Control-Allow-Credentials "true" always;
add_header Access-Control-Allow-Methods "GET,POST,OPTIONS" always;
add_header Access-Control-Allow-Headers "$CORS_ALLOW_HEADERS" always;
add_header Access-Control-Max-Age 86400 always;
return 204; # 204 No Content is conventional for pre‑flight
}
# --- authenticated requests ---
if ($is_authorized = 0) {
return 401;
}
proxy_pass http://gateway:3000;
proxy_set_header Host $host;
# expose CORS headers on the real response too
add_header Access-Control-Allow-Origin "$CORS_ALLOW_ORIGIN" always;
add_header Access-Control-Allow-Credentials "true" always;
}
}
}
```
</file_contents>
<manually_added_selection>
```path=nginx/nginx.conf, lines=1-16
events {}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent"';
access_log /var/log/nginx/access.log main;
map $http_authorization $is_authorized {
default 0;
"~*^Bearer your-token-here$" 1;
}
server {
listen 80;
```
</manually_added_selection>
</attached_files>
</additional_data>
<user_query>
how do I get nginx to get the key from an environment variable in my .env?
</user_query>Response
I see you're trying to use an environment variable for your authentication token in the Nginx configuration instead of hardcoding "your-token-here" in the `nginx.conf` file.
Unfortunately, Nginx doesn't directly read environment variables from a `.env` file. However, there are a few approaches you can take:
### Option 1: Use Nginx's environment variable support with a template
1. Create a template file (e.g., `nginx.conf.template`) with a placeholder:
```
map $http_authorization $is_authorized {
default 0;
"~*^Bearer ${API_TOKEN}$" 1;
}
```
2. Then use a script to replace the placeholder with the actual environment variable before starting Nginx:
```bash
#!/bin/bash
# Load environment variables from .env
source .env
# Replace placeholder with actual token
envsubst '${API_TOKEN}$' < /path/to/nginx.conf.template > /path/to/nginx.conf
# Start Nginx
nginx -g 'daemon off;'
```
### Option 2: Use Docker environment variables (if using Docker)
If you're running Nginx in Docker, you can pass environment variables to the container and use `envsubst`:
```dockerfile
FROM nginx:alpine
COPY nginx.conf.template /etc/nginx/templates/default.conf.template
CMD ["/bin/sh", "-c", "envsubst '${API_TOKEN}$' < /etc/nginx/templates/default.conf.template > /etc/nginx/conf.d/default.conf && nginx -g 'daemon off;'"]
```
Then run with:
```bash
docker run -e API_TOKEN=your-secret-token -p 80:80 your-nginx-image
```
### Option 3: Use a separate authentication service
Instead of hardcoding the token in Nginx, you could proxy authentication requests to a separate service that has access to environment variables:
```
location /auth {
proxy_pass http://auth-service:3001;
# This service can read environment variables
}
```
For your specific case, I'd recommend Option 1 or 2 depending on your deployment setup. This way, you can keep your token in your `.env` file and have it securely injected into the Nginx configuration at startup time.Prompt Engineering Cursor
This example paints a picture of what prompt engineering looks like for a state-of-the-art AI coding assistant.
This prompt and others like it (there were different prompts used for asking questions, editing source code, and working in the shell) are all Cursor uses to answer questions and generate code. We find it remarkable that there isn’t more here and that all of software engineering has been internalized enough by the current generation of LLMs that you can get the brains behind Cursor with a 642-token system prompt. This must be due to extensive post-training efforts by the big labs.
An Explicit AI Hierarchy?
We find the following snippet particularly intriguing:
These edit codeblocks are also read by a less intelligent language model, colloquially called the apply model, to update the file. To help specify the edit to the apply model, you will [...]. You will not mention the apply model.It’s common to mix different models to optimize cost and latency, but Cursor explains this hierarchy to the models themselves? Interesting.
A/B Testing Models
With TensorZero in place, we have the full Cursor experience with control over observability and experimentation of our LLM requests. We’ve been running CursorZero for days of heavy software engineering: it’s been stable and there has been no noticeable additional latency.
We’re currently running an even random split of Claude 4.0 Sonnet, GPT-4.1, o4 Mini, and Gemini 2.5 Pro — and it feels as good as Cursor ever has.
Try It Yourself
Interested in analyzing your own usage of AI coding assistants? You can find instructions on GitHub to reproduce this work with Cursor and OpenAI Codex.
TensorZero helps you understand — and optimize — your LLM agents, even if you didn’t build them yourself!
But Wait… There’s More!
This blog post demonstrates how we successfully reverse-engineered Cursor’s LLM client by setting up TensorZero as a self-hosted proxy service, enabling us to observe, analyze, and experiment with different LLM models while maintaining the full Cursor experience.
In our next post of this series, we’ll explain how we’re evaluating real-world usage of AI coding assistants, along with the results of our internal A/B testing between models. Sneak peek: git hooks, tree-sitter, and more.
Then, we’ll explore if this feedback signal might be able to improve Cursor by optimizing models and inferences through your individual usage patterns.
Stay tuned by subscribing below.