- Inference: Call the
generate_database_queryTensorZero function to generate a database query from the user’s question. - Custom Logic: Run the database query against a database and retrieve the results (
my_blackbox_search_function). - Inference: Call the
generate_final_answerTensorZero function to generate an answer from the retrieved results. - Custom Logic: Score the answer using a custom scoring function (
my_blackbox_scoring_function) - Feedback: Send feedback using the
task_successmetric.
generate_database_query and generate_final_answer in a vacuum (i.e. using inference evaluations) can also be helpful, but ultimately we want to evaluate the entire workflow end-to-end.
This is where workflow evaluations come in.
Complex LLM applications might need to make multiple LLM calls and execute arbitrary code before giving an overall result.
In agentic applications, the workflow might even be defined dynamically at runtime based on the user’s input, the results of the LLM calls, or other factors.
Workflow evaluations in TensorZero provide complete flexibility and enable you to evaluate the entire workflow jointly.
You can think of them like integration tests for your LLM applications.
Starting a workflow evaluation run
Evaluating the workflow above involves tackling and evaluating a collection of tasks (e.g. user queries). Each individual task corresponds to an episode, and the collection of these episodes is a workflow evaluation run.- Python
- Python (Async)
- HTTP
First, let’s initialize the TensorZero client (just like you would for typical inference requests):Now you can start a workflow evaluation run.During a workflow evaluation run, you specify which variants you want to pin during the run (i.e. the set of variants you want to evaluate).
This allows you to see the effects of different combinations of variants on the end-to-end system’s performance.You can optionally also specify a
project_name and display_name for the run.
If you specify a project_name, you’ll be able to compare this run against other runs for that project using the TensorZero UI.
The display_name is a human-readable identifier for the run that you can use to identify the run in the TensorZero UI.Starting an episode in a workflow evaluation run
For each task we want to include in our workflow evaluation run, we need to start an episode. For example, in our agentic RAG project, each episode will correspond to a user query from our dataset; each user query requires multiple inference calls and application logic to run.- Python
- Python (Async)
- HTTP
To initialize an episode, you need to provide the Now we can use
run_id of the workflow evaluation run you want to include the episode in.
You can optionally also specify a task_name for the episode.
If you specify a task_name, you’ll be able to compare this episode against episodes for that task from other runs using the TensorZero UI.
We encourage you to use the task_name to provide a meaningful identifier for the task that the episode is tackling.episode_info.episode_id to make inference and feedback calls.Making inference and feedback calls during a workflow evaluation run
You can use the OpenAI SDK for inference calls by pointing it at the TensorZero Gateway. Pass theepisode_id from the workflow evaluation run episode via extra_body so that inferences are associated with the evaluation run.
(Similarly, you can also use workflow evaluations with any framework or agent that is OpenAI-compatible by passing along the episode ID and function name in the request to TensorZero.)
- Python
- Python (Async)
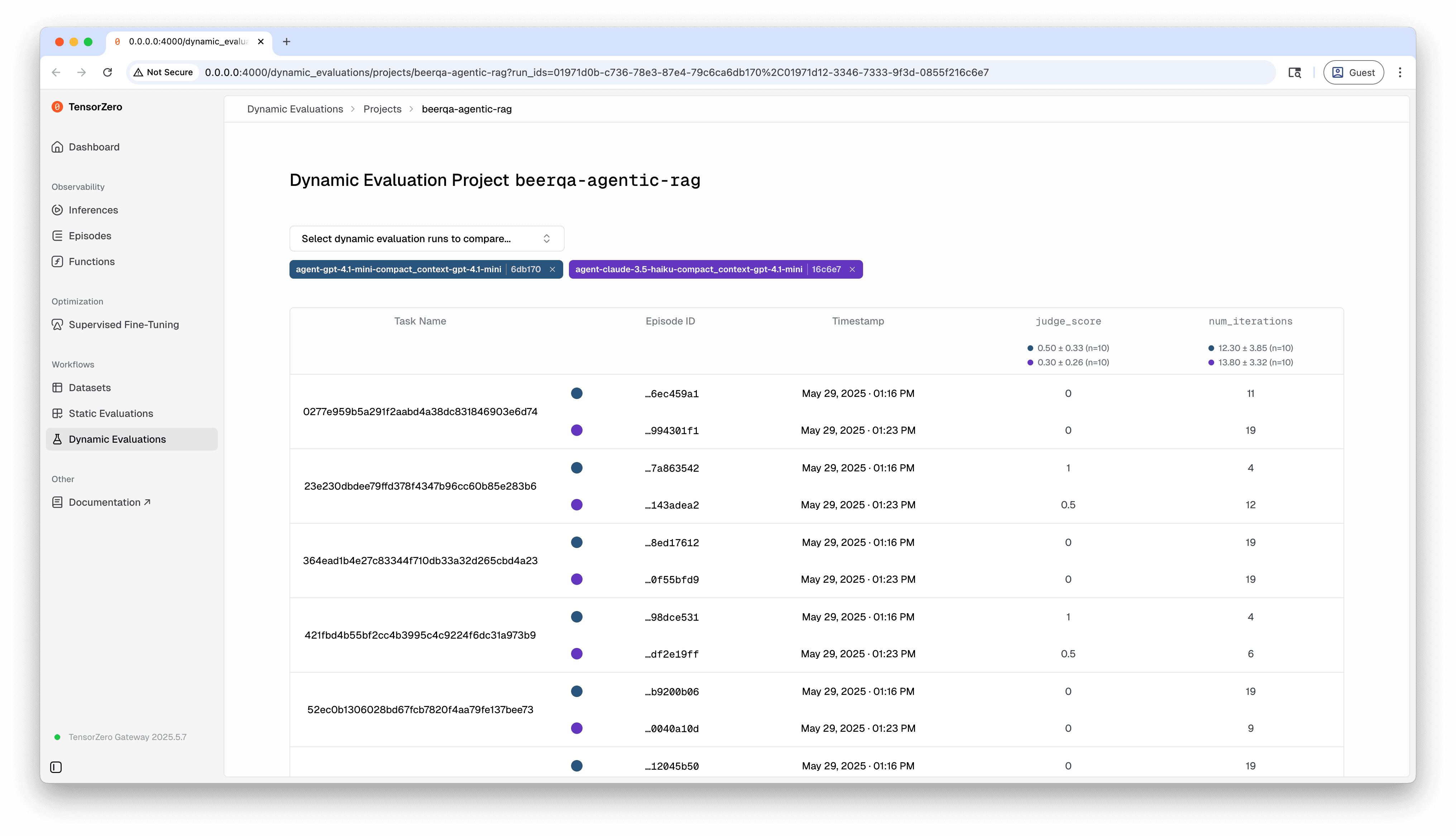
Visualizing evaluation results in the TensorZero UI
Once you finish running all the relevant episodes for your workflow evaluation run, you can visualize the results in the TensorZero UI. In the UI, you can compare metrics across evaluation runs, inspect individual episodes and inferences, and more.