TensorZero Autopilot is an automated AI engineer that analyzes LLM observability data, optimizes prompts and models, sets up evals, and runs A/B tests. Schedule a demo →
Learn how to use the TensorZero Inference Evaluations to build principled LLM-powered applications.
This guide shows how to define and run inference evaluations for your TensorZero functions.
See our Quickstart to learn how to set up our LLM gateway, observability, and fine-tuning — in just 5 minutes.
You can find the code behind this tutorial and instructions on how to run it on GitHub.Reach out on Slack or Discord if you have any questions. We’d be happy to help!
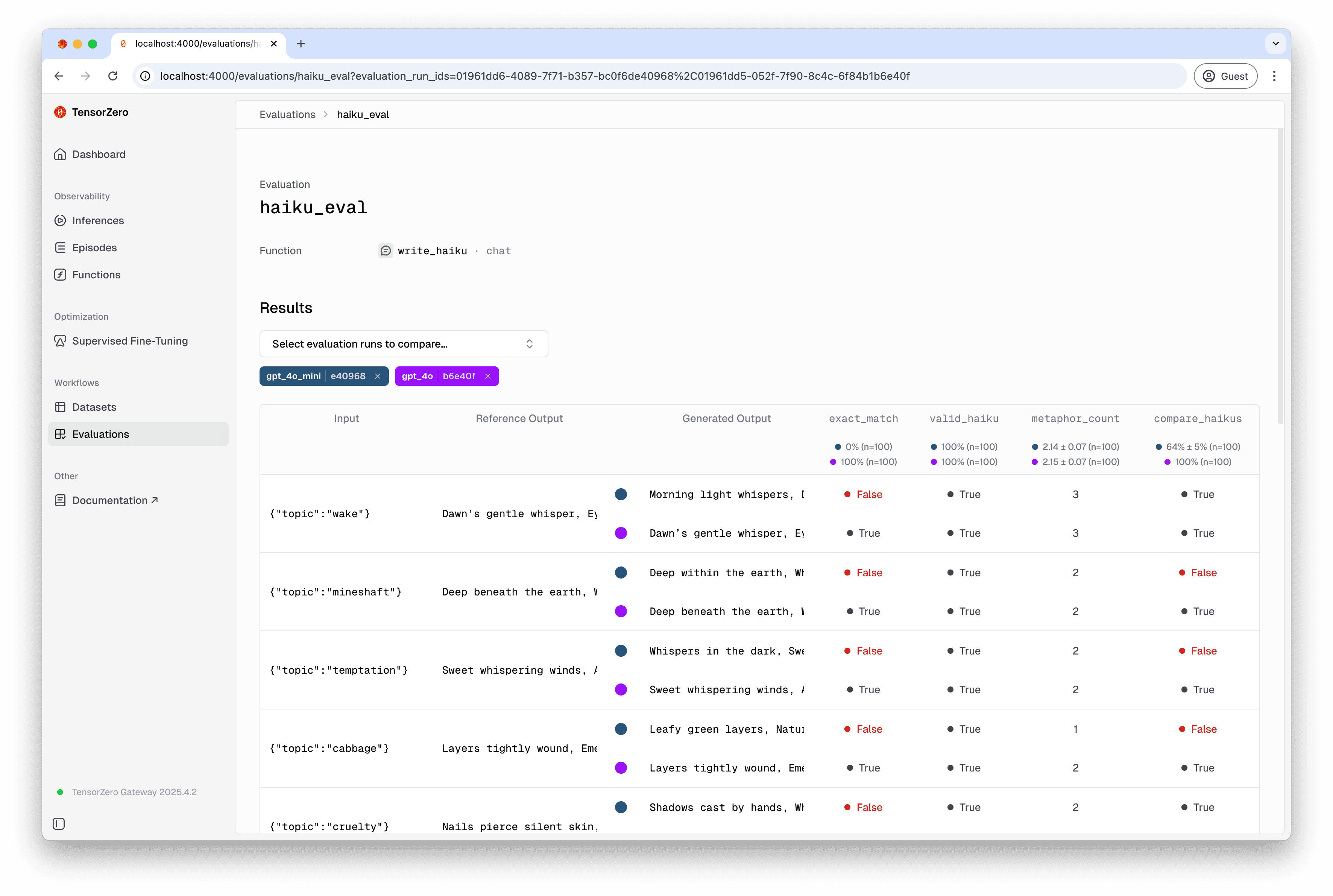
Imagine we have a TensorZero function for writing haikus about a given topic, and want to compare the behavior of GPT-4o and GPT-4o Mini on this task.Initially, our configuration for this function might look like:
How can we evaluate the behavior of our two variants in a principled way?One option is to build a dataset of “test cases” that we can evaluate them against.
To use TensorZero Evaluations, you first need to build a dataset.A dataset is a collection of datapoints.
Each datapoint has an input and optionally a output.
In the context of evaluations, the output in the dataset should be a reference output, i.e. the output you’d have liked to see.
You don’t necessarily need to provide a reference output: some evaluators (e.g. LLM judges) can score generated outputs without a reference output (otherwise, that datapoint is skipped).Let’s create a dataset:
Generate many haikus by running inference on your write_haiku function. (On GitHub, we provide a script main.py that generates 100 haikus with write_haiku.)
Open the UI, navigate to “Datasets”, and select “Build Dataset” (http://localhost:4000/datasets/builder).
Create a new dataset called haiku_dataset.
Select your write_haiku function, “None” as the metric, and “Inference” as the dataset output.
Evaluators are defined as part of a function’s configuration.
Each evaluator defines a rule or behavior you’d like to test.We’re going to configure our write_haiku function with two types of evaluators: exact_match and llm_judge.
See the Evaluations Configuration Reference for the full list of supported evaluator types.
The exact_match evaluator compares the generated output with the datapoint’s reference output.
If they are identical, it returns true; otherwise, it returns false.
LLM Judges are special-purpose TensorZero function that can be used to evaluate a TensorZero function.For example, our haikus should generally follow a specific format, but it’s hard to define a heuristic to determine if they’re correct.
Why not ask an LLM?Let’s do that:
[functions.write_haiku.evaluators.valid_haiku]type = "llm_judge"output_type = "boolean" # LLM judge should generate a boolean (or float)optimize = "max" # higher is better[functions.write_haiku.evaluators.valid_haiku.variants.gpt_4o_mini_judge]type = "chat_completion"model = "openai::gpt-4o-mini"system_instructions = "functions/write_haiku/evaluators/valid_haiku/system_instructions.txt"json_mode = "strict"
Evaluate if the text follows the haiku structure of exactly three lines with a 5-7-5 syllable pattern, totaling 17 syllables. Verify only this specific syllable structure of a haiku without making content assumptions.
Here, we defined an evaluator valid_haiku of type llm_judge, with a variant that uses GPT-4o Mini.Similar to regular TensorZero functions, we can define multiple variants for an LLM judge.
But unlike regular functions, only one variant can be active at a time during evaluation; you can denote that with the active property.
The LLM judge we showed above generates a boolean, but they can also generate floats.Let’s define another evalutor that counts the number of metaphors in our haiku.
[functions.write_haiku.evaluators.metaphor_count]type = "llm_judge"output_type = "float" # LLM judge should generate a boolean (or float)optimize = "max"
We can also use different variant types for evaluators.
Let’s use a chain-of-thought variant for our metaphor count evaluator, since it’s a bit more complex.
The LLM judges we’ve defined so far only look at the datapoint’s input and the generated output.
But we can also provide the datapoint’s reference output to the judge:
[functions.write_haiku.evaluators.compare_haikus]type = "llm_judge"include = { reference_output = true } # include the reference output in the LLM judge's contextoutput_type = "boolean"optimize = "max"[functions.write_haiku.evaluators.compare_haikus.variants.gpt_4o_mini_judge]type = "chat_completion"model = "openai::gpt-4o-mini"system_instructions = "functions/write_haiku/evaluators/compare_haikus/system_instructions.txt"json_mode = "strict"
Let’s run our evaluations!You can run evaluations using the TensorZero Evaluations CLI tool or the TensorZero UI.
The TensorZero Evaluations CLI tool can be helpful for CI/CD.
It’ll exit with code 0 if all evaluations succeed, or code 1 otherwise.
Use --cutoffs to enforce pass/fail thresholds from the CLI.
By default, TensorZero Evaluations uses Inference Caching to improve inference speed and cost.
Here’s the relevant section of the docker-compose.yml for the evaluations tool.You should provide credentials for any LLM judges.
Alternatively, the evaluations tool can use an external TensorZero Gateway with the --gateway-url http://gateway:3000 flag.
services: # ... evaluations: profiles: [evaluations] image: tensorzero/evaluations volumes: - ./config:/app/config:ro environment: OPENAI_API_KEY: ${OPENAI_API_KEY:?Environment variable OPENAI_API_KEY must be set.} # ... and any other relevant API credentials ... TENSORZERO_POSTGRES_URL: postgres://postgres:postgres@postgres:5432/tensorzero extra_hosts: - "host.docker.internal:host-gateway" depends_on: postgres: condition: service_healthy# ...
See GitHub for the complete Docker Compose configuration.
Docker Compose does not start this service with docker compose up since we have profiles: [evaluations].
You need to call it explicitly with docker compose run evaluations, as desired.
To run evaluations in the UI, navigate to “Evaluations” (http://localhost:4000/evaluations) and select “New Run”.You can compare multiple evaluation runs in the TensorZero UI (including evaluation runs for the CLI).