Documentation Index
Fetch the complete documentation index at: https://www.tensorzero.com/docs/llms.txt
Use this file to discover all available pages before exploring further.
Inference-time optimizations are powerful techniques that can significantly enhance the performance of your LLM applications without the need for model fine-tuning.
This guide will explore three key strategies implemented as variant types in TensorZero: Best-of-N (BoN) sampling, Dynamic In-Context Learning (DICL), and Mixture-of-N (MoN) sampling.
Dynamic In-Context Learning enhances context by incorporating relevant historical examples into the prompt.
Best-of-N and Mixture-of-N sampling both generate multiple response candidates; Best-of-N selects the best one using an evaluator model, while Mixture-of-N combines the responses using a fuser model.
All three techniques can lead to improved response quality and consistency in your LLM applications.
Best-of-N Sampling
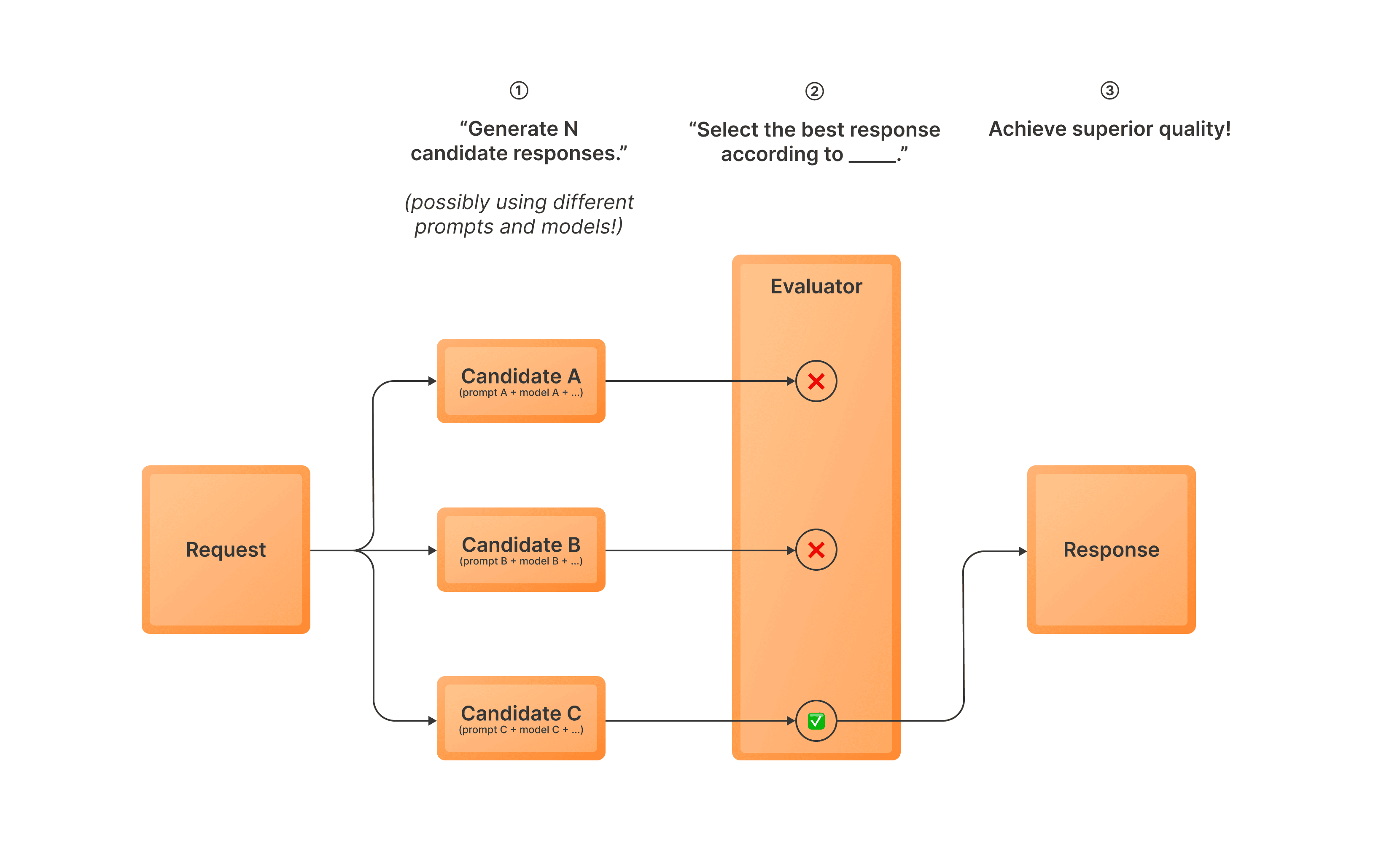 Best-of-N (BoN) sampling is an inference-time optimization strategy that can significantly improve the quality of your LLM outputs.
Here’s how it works:
Best-of-N (BoN) sampling is an inference-time optimization strategy that can significantly improve the quality of your LLM outputs.
Here’s how it works:
- Generate multiple response candidates using one or more variants (i.e. possibly using different models and prompts)
- Use an evaluator model to select the best response from these candidates
- Return the selected response as the final output
This approach allows you to leverage multiple prompts or variants to increase the likelihood of getting a high-quality response.
It’s particularly useful when you want to benefit from an ensemble of variants or reduce the impact of occasional bad generations.
Best-of-N sampling is also commonly referred to as rejection sampling in some contexts.
To use BoN sampling in TensorZero, you need to configure a variant with the experimental_best_of_n type.
Here’s a simple example configuration:
[functions.draft_email.variants.promptA]
type = "chat_completion"
model = "gpt-4o-mini"
user_template = "functions/draft_email/promptA/user.minijinja"
[functions.draft_email.variants.promptB]
type = "chat_completion"
model = "gpt-4o-mini"
user_template = "functions/draft_email/promptB/user.minijinja"
[functions.draft_email.variants.best_of_n]
type = "experimental_best_of_n"
candidates = ["promptA", "promptA", "promptB"]
[functions.draft_email.variants.best_of_n.evaluator]
model = "gpt-4o-mini"
user_template = "functions/draft_email/best_of_n/user.minijinja"
[functions.draft_email.experimentation]
type = "static"
candidate_variants = ["best_of_n"] # so we don't sample `promptA` or `promptB` directly
- We define a
best_of_n variant that uses two different variants (promptA and promptB) to generate candidates.
It generates two candidates using promptA and one candidate using promptB.
- The
evaluator block specifies the model and instructions for selecting the best response.
You should define the evaluator model as if it were solving the problem (not judging the quality of the candidates).
TensorZero will automatically make the necessary prompt modifications to evaluate the candidates.
experimental_best_of_n variant type in Configuration Reference.
Dynamic In-Context Learning (DICL)
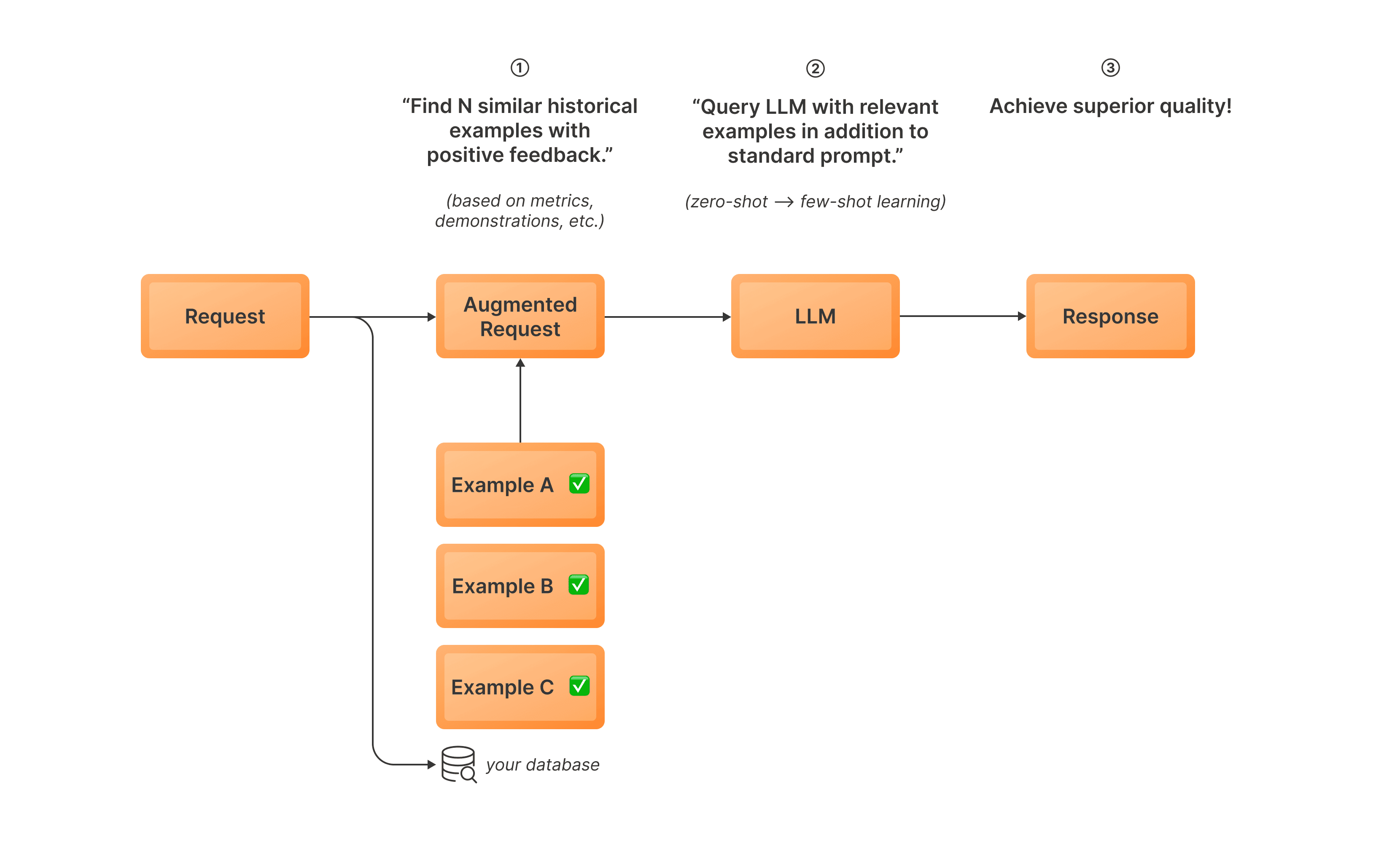 Dynamic In-Context Learning (DICL) is an inference-time optimization that improves LLM performance by incorporating relevant historical examples into your prompt.
Instead of incorporating static examples manually in your prompts, DICL selects the most relevant examples at inference time.
See the Dynamic In-Context Learning (DICL) Guide to learn more.
Dynamic In-Context Learning (DICL) is an inference-time optimization that improves LLM performance by incorporating relevant historical examples into your prompt.
Instead of incorporating static examples manually in your prompts, DICL selects the most relevant examples at inference time.
See the Dynamic In-Context Learning (DICL) Guide to learn more.
Mixture-of-N Sampling
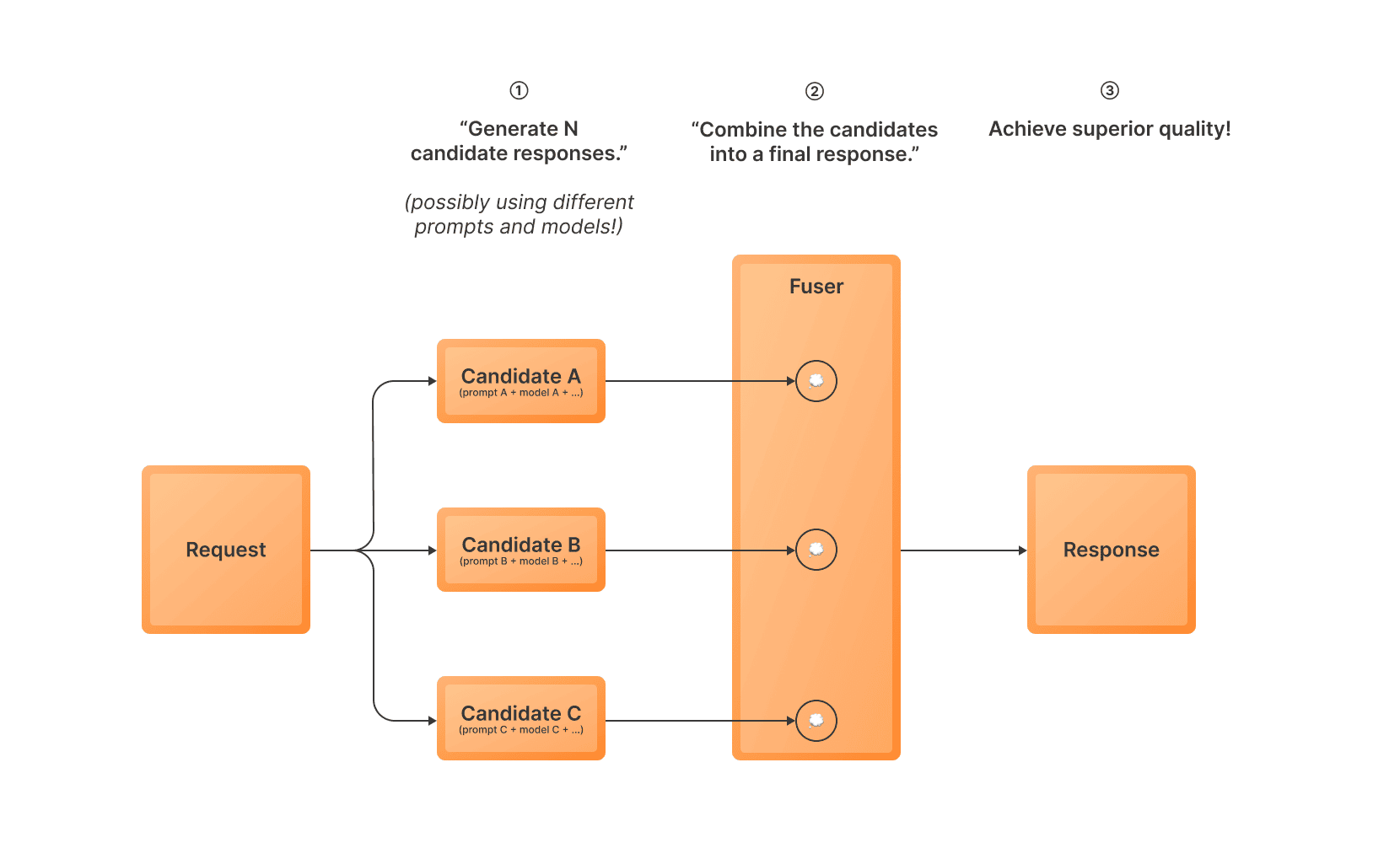 Mixture-of-N (MoN) sampling is an inference-time optimization strategy that can significantly improve the quality of your LLM outputs.
Here’s how it works:
Mixture-of-N (MoN) sampling is an inference-time optimization strategy that can significantly improve the quality of your LLM outputs.
Here’s how it works:
- Generate multiple response candidates using one or more variants (i.e. possibly using different models and prompts)
- Use a fuser model to combine the candidates into a single response
- Return the combined response as the final output
This approach allows you to leverage multiple prompts or variants to increase the likelihood of getting a high-quality response.
It’s particularly useful when you want to benefit from an ensemble of variants or reduce the impact of occasional bad generations.
To use MoN sampling in TensorZero, you need to configure a variant with the experimental_mixture_of_n type.
Here’s a simple example configuration:
[functions.draft_email.variants.promptA]
type = "chat_completion"
model = "gpt-4o-mini"
user_template = "functions/draft_email/promptA/user.minijinja"
[functions.draft_email.variants.promptB]
type = "chat_completion"
model = "gpt-4o-mini"
user_template = "functions/draft_email/promptB/user.minijinja"
[functions.draft_email.variants.mixture_of_n]
type = "experimental_mixture_of_n"
candidates = ["promptA", "promptA", "promptB"]
[functions.draft_email.variants.mixture_of_n.fuser]
model = "gpt-4o-mini"
user_template = "functions/draft_email/mixture_of_n/user.minijinja"
[functions.draft_email.experimentation]
type = "static"
candidate_variants = ["mixture_of_n"] # so we don't sample `promptA` or `promptB` directly
- We define a
mixture_of_n variant that uses two different variants (promptA and promptB) to generate candidates.
It generates two candidates using promptA and one candidate using promptB.
- The
fuser block specifies the model and instructions for combining the candidates into a single response.
You should define the fuser model as if it were solving the problem (not judging the quality of the candidates).
TensorZero will automatically make the necessary prompt modifications to combine the candidates.
experimental_mixture_of_n variant type in Configuration Reference.