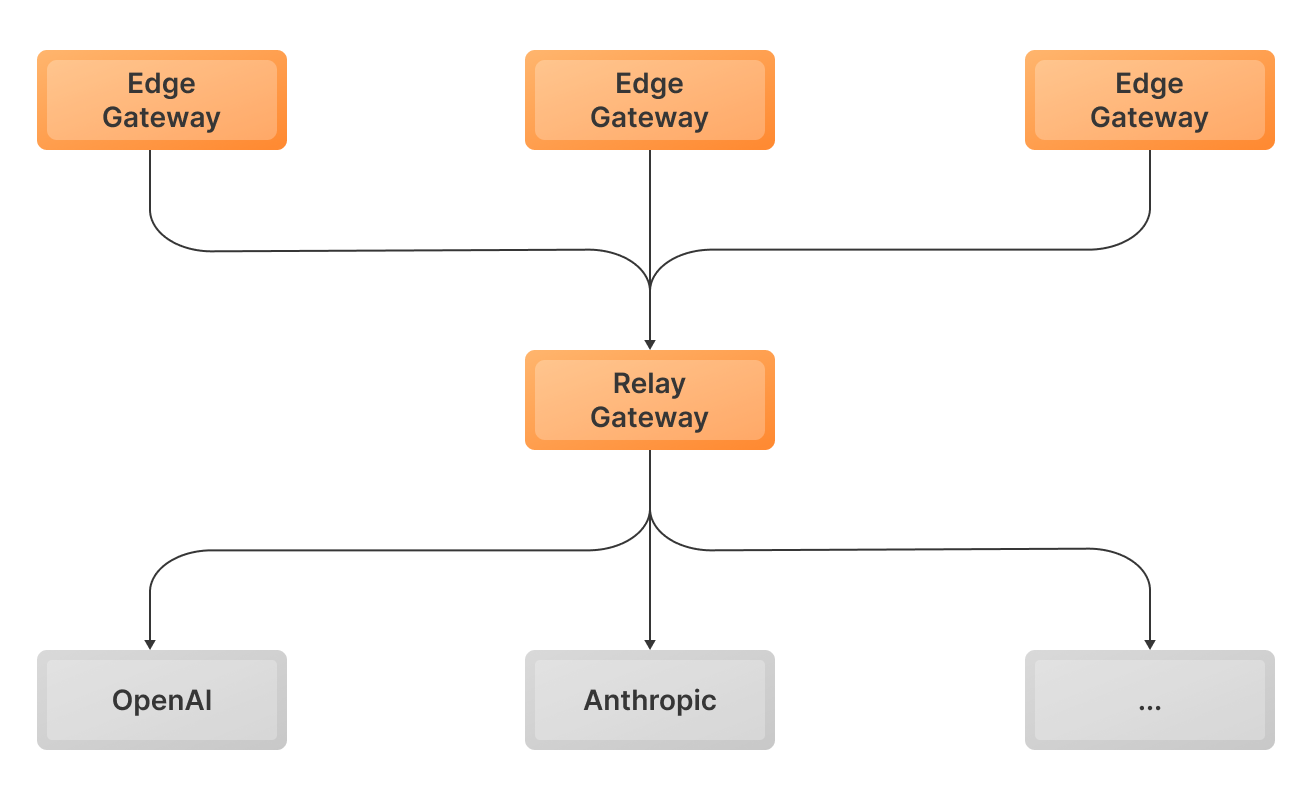
With gateway relay, an LLM inference request can be routed through multiple independent TensorZero Gateway deployments before reaching a model provider. This enables you to enforce organization-wide controls (e.g. auth, rate limits, credentials) without restricting how teams build their LLM features. A typical setup has two tiers:Documentation Index
Fetch the complete documentation index at: https://www.tensorzero.com/docs/llms.txt
Use this file to discover all available pages before exploring further.
- Edge Gateways: Each team runs their own gateway to manage prompts, functions, metrics, datasets, experimentation, and more.
- Relay Gateway: A central gateway enforces organization-wide controls. Edge gateways forward requests here.
Configure
Configure your relay gateway
You can configure auth, rate limits, credentials, and other organization-wide controls in the relay gateway. See below for an example that enforces auth on the relay.We’ll keep this example minimal and use the default gateway configuration for the relay gateway.
Configure your edge gateway
Configure the edge gateway to route inference requests to the relay gateway:
edge-config/tensorzero.toml
Deploy both gateways
Let’s deploy both gateways, but only provide API keys to the relay gateway.
docker-compose.yml
Advanced
Set up auth for the relay gateway
You can set up auth for the relay gateway to control which edge gateways are allowed to forward requests through it. This ensures that only authorized teams can access the relay gateway and helps you enforce security policies across your organization. When auth is enabled on the relay gateway, edge gateways must provide valid credentials (API keys) to authenticate their requests.Configure auth for the relay gateway
relay-config/tensorzero.toml
Configure credentials in the edge gateway
Add Finally, provide the API key to the edge gateway:See Configuration Reference for more details on
api_key_location to your edge gateway’s configuration and provide the relevant credentials.For example, let’s configure the gateway to look for the API key in the TENSORZERO_RELAY_API_KEY environment variable:edge-config/tensorzero.toml
api_key_location.Bypass the relay for specific requests
When a relay gateway is configured, the edge gateway will route every inference request through it by default. However, you may want to bypass the relay in some scenarios. You can circumvent the relay for specific requests by configuring a custom model withskip_relay = true in the edge gateway:
edge-config/tensorzero.toml
gpt_5_edge model, the edge gateway will bypass the relay and call OpenAI directly using credentials available on the edge gateway.
The edge gateway must have the necessary provider credentials configured to make direct requests.
Models that skip the relay won’t benefit from centralized rate limits, auth policies, or credential management enforced by the relay gateway.
Set up dynamic credentials for the relay gateway
You can pass provider credentials dynamically at inference time, and the edge gateway will forward them to the relay gateway.Configure the relay gateway to expect dynamic credentials
relay-config/tensorzero.toml